Abstract
Human memory for abstract visuals is notably poorer than for real-world scenes. We investigated whether this discrepancy stems from the difficulty in verbally labeling abstract content. We utilize a set of abstract images that vary in their complexities and human memory performance on those images to test our hypothesis. Using LLMs to generate captions for these abstract images of varying complexity, we found that caption complexity mirrored visual complexity. We built several simple models to predict human memory performance on abstract images and found that a predictive model based on the generated captions' semantic content performed competitively to a model relying solely on visual features. This study suggests that our ability to verbalize and name what we are seeing might indeed underpin our ability to remember a visual scene.
Schematic Figure
Introduction / Background / Motivation
What did you try to do? What problem did you try to solve? Articulate your objectives using absolutely no jargon.
We began with the question why some pictures are harder to remember than others. We wanted to see why we remember so many details about the natural world and much less so when encountering abstract images. We wanted to check if the reason why abstract scenes are more challenging is because they are hard to describe with words. For natural scenes, we have names and labels for things which might aid our memory, but maybe as our linguistic aids gets reduced with abstract scenes, we have worse memory for them. As a result, we tested multiple abstract images with varying complexity to check if there's a link between how difficult it is to describe a complex and how challenging it is to remember it.
How is it done today, and what are the limits of current practice?
It involves generating captions for abstract images and no LLM model to our knowledge is tailored for it. Most psychological and neuroscience experiments use synthetic, non-natural images so obtaining any semantic information on them is impossible as the computational models don't focus on them. As such this involves careful prompt engineering to use existing LLMs to generate captions for non-natural images.
Who cares? If you are successful, what difference will it make?
Psychologists and neuroscientists, specifically computational neuroscientists and perception researchers as this can provide an novel way to understand the interplay between visual memory and our thoughts which are linguistic. It can also benefit VLM research in the computer science community,.
Approach
What did you do exactly? How did you solve the problem? Why did you think it would be successful? Is anything new in your approach?
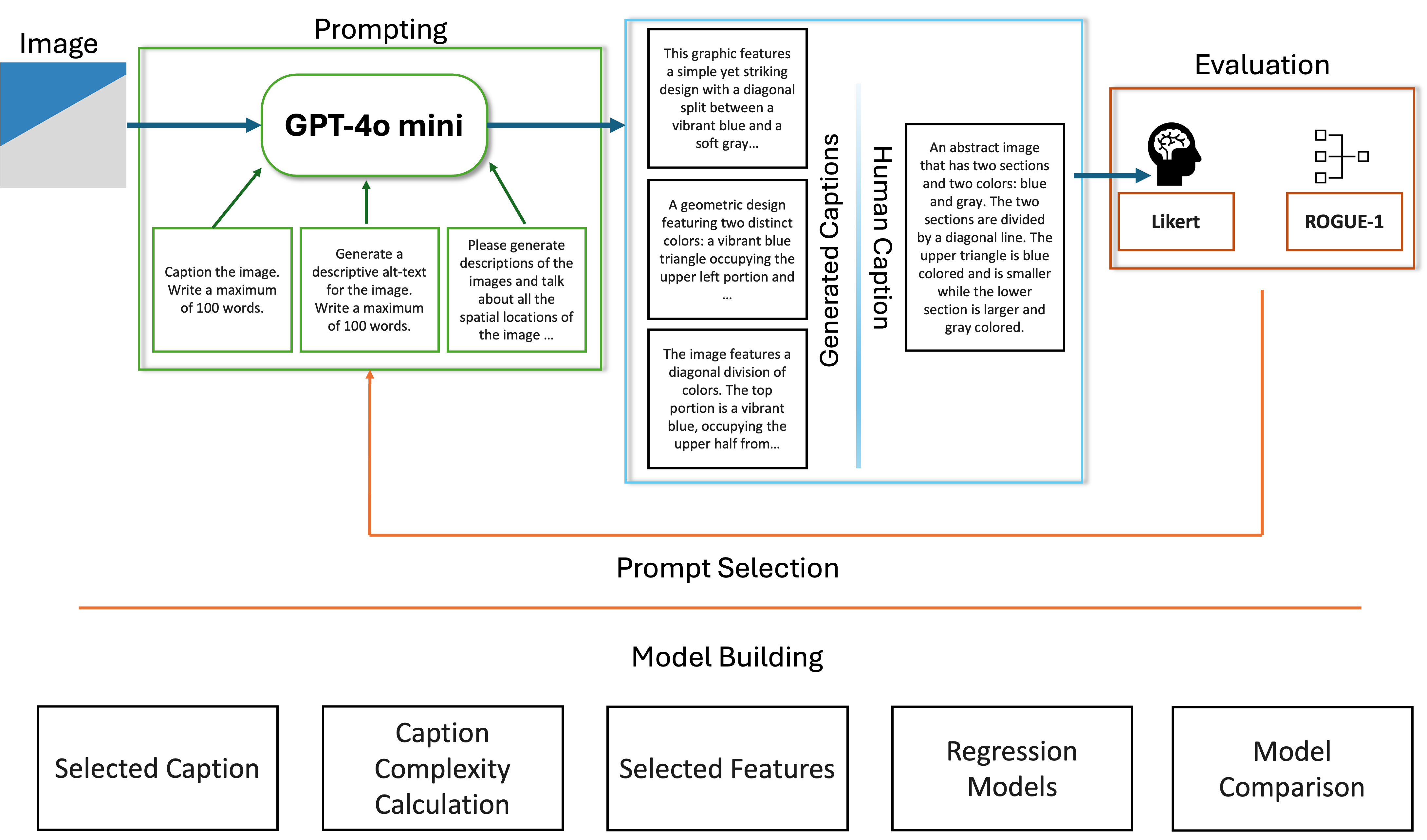
The methodology involves generating captions for abstract images using a GPT-4 model with carefully engineered prompts, evaluated using both automatic and human metrics to select the best prompt. Semantic complexity was quantified using perplexity (from a pretrained BERT model) and concreteness (using WordNet synset depths). Regression models were trained with these semantic complexity features to predict human memory performance, validated through K-fold cross-validation with image blocks as folds.
What problems did you anticipate? What problems did you encounter? Did the very first thing you tried work?
The main challenges included the limited ability of existing LLMs to accurately describe abstract images due to a lack of training on such stimuli, often defaulting to naturalistic interpretations. Extensive prompt engineering was required to guide the models effectively, which was labor-intensive. Additionally, readability metrics like Flesch scores were tested but found unsuitable, and the dataset was limited to 27 images and 6 participants, constraining the study’s scale and generalizability.
Results
How did you measure success? What experiments were used? What were the results, both quantitative and qualitative? Did you succeed? Did you fail? Why?
Recent work has shown that as image complexity
increases, human memory performance declines
for abstract images
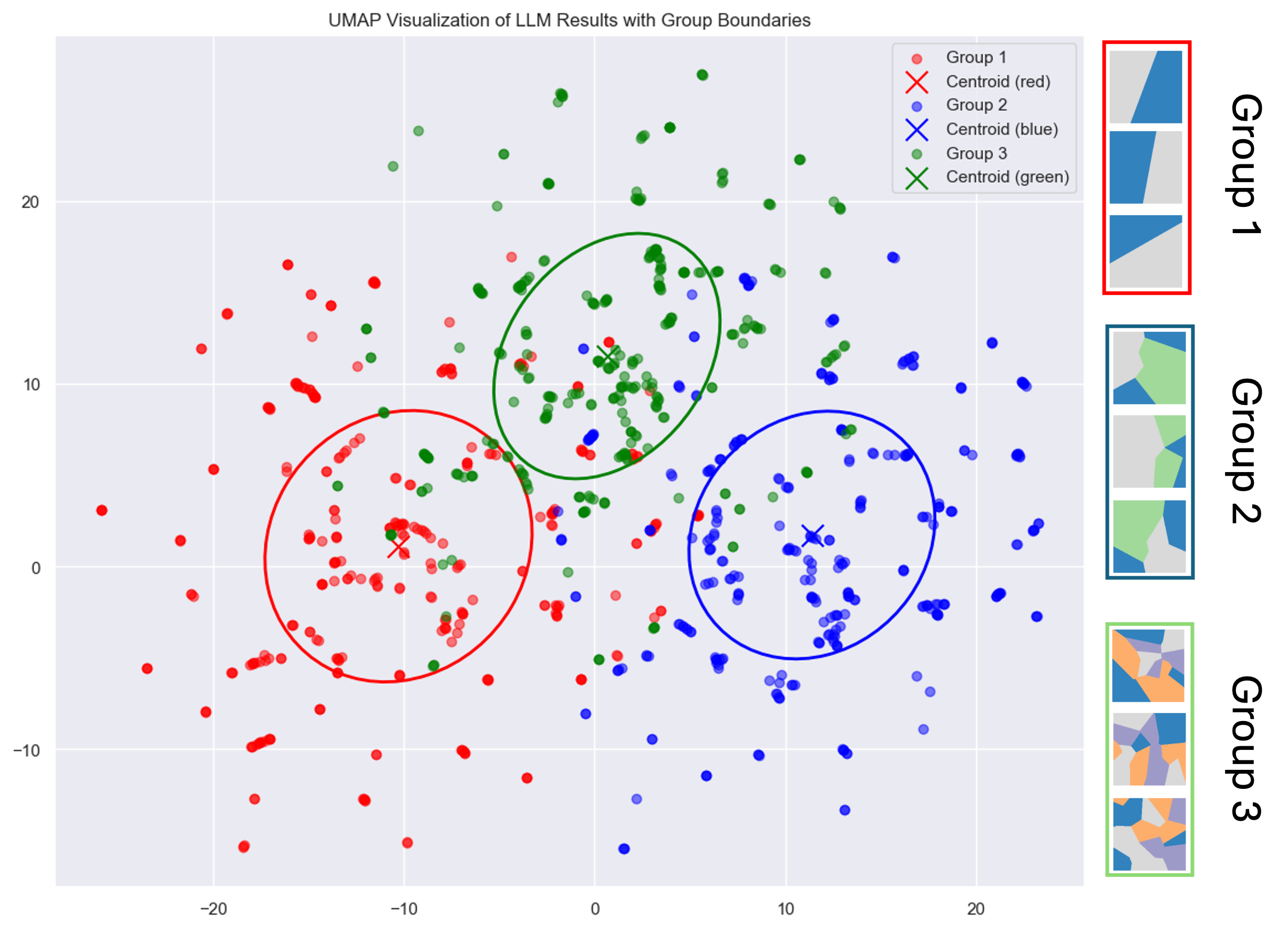
A UMAP (Uniform Manifold Approximation
and Projection) of the captions of select group of images was used to cluster
captions generated for abstract images by their caption complexity. The UMAP demonstrates clear
separation among captions based on their associated image complexities. This separation indicates that the captions, reflect underlying patterns of image complexity that humans
intuitively perceive
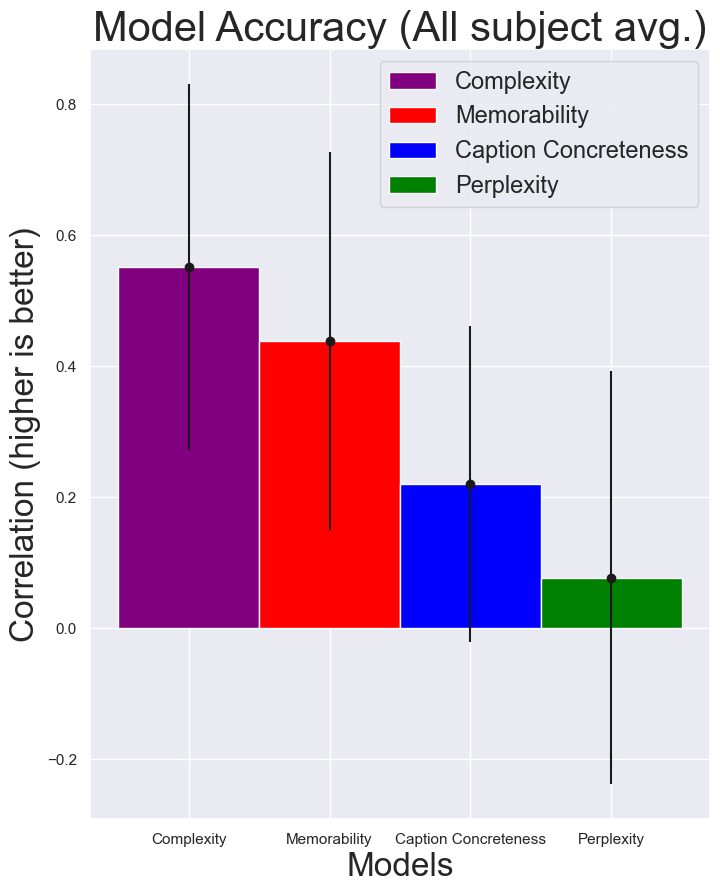
We also compared the performance of models
predicting memory performance using different
semantic complexity metrics. A
K-Fold cross-validation approach was employed
to rigorously compare a semantic memorability
model (based on a linear combination of perplexity
and concreteness) with a purely visual complexity
model. Remarkably, the semantic model proved
competitive with the visual complexity model, underscoring the importance of semantic factors in
determining memorability.
Conclustion and Future Work
Overall, the results strongly support the idea that semantic descriptions aid visual memory. They reveal
a robust connection between image complexity, semantic representation, and memory performance,
shedding light on why natural scenes are easier to
remember than abstract ones. The implications of
this study extend to areas such as AI-driven image
captioning, memory training, and understanding
the cognitive basis of visual and semantic integration.
In this study, we quantitatively analyzed human visual memory performance through semantic
means by leveraging metrics such as perplexity and
concreteness. These metrics serve as proxies for
the difficulty of generating semantic descriptions,
revealing that abstract images with higher visual
complexity lack clear semantic cues, leading to increased memory recall errors. This supports the
hypothesis that humans rely on both visual and
semantic representations to encode and retrieve
memories, with the absence of semantic anchors in
abstract images impairing memory performance.
Our UMAP analysis demonstrated that captions
for less complex images cluster tightly, reflecting straightforward semantic structures, while captions
for more complex images are dispersed, indicating
greater variability and difficulty in interpretation.
This suggests that semantic properties are closely
tied to visual complexity, offering new insights
into how image semantics influence cognitive processes.